
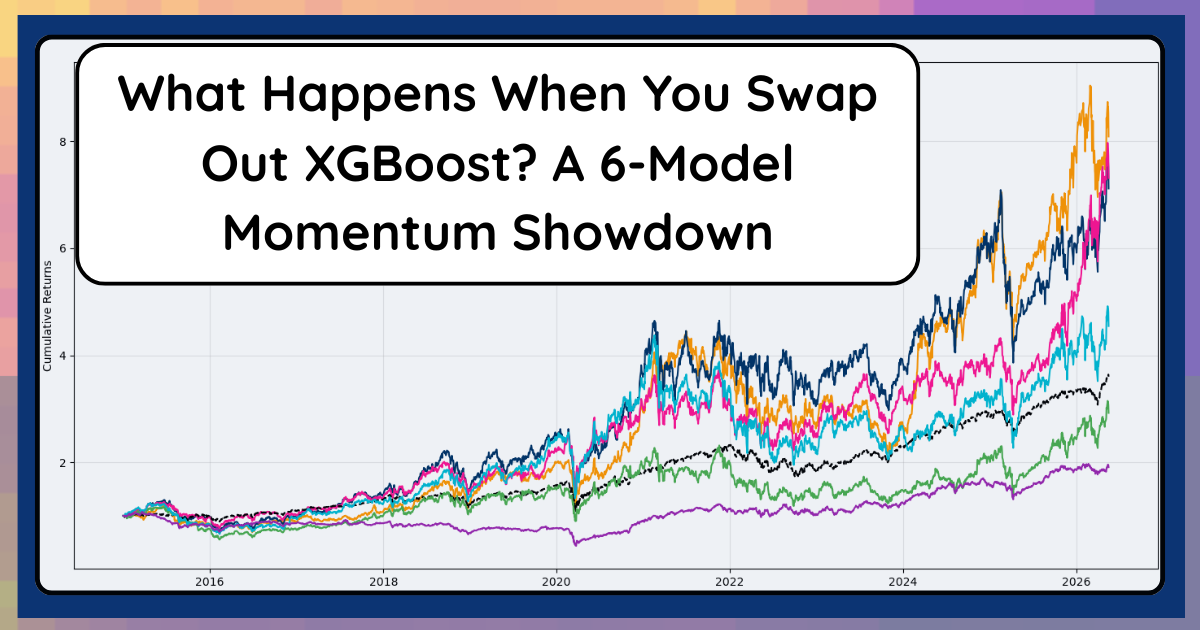
What Happens When You Swap Out XGBoost? A 6‑Model Momentum Showdown
Comparing XGBoost, LightGBM, CatBoost, Random Forest, LASSO, and a Neural Net in the same momentum trading system using identical features and backtests. All three GBMs beat the S&P on default settings.